
📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark shows that no AI model is universally superior across all defense-relevant criteria. Rankings vary based on user needs, highlighting the importance of context in model selection.
The VigilSAR Benchmark has demonstrated that there is no single, universally best AI model for defense and intelligence applications. Instead, the suitability of a model depends heavily on the specific needs and constraints of the user, such as deployment environment, compliance requirements, and reliability. This challenges the common perception that the highest capability models are always the optimal choice for deployment in sensitive settings.
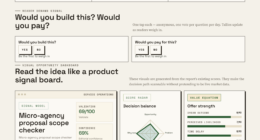
The VigilSAR Benchmark evaluates models on five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. It scores models across eight knowledge domains relevant to defense, explicitly excluding offensive capabilities like weaponization or exploit generation. The benchmark emphasizes that a model’s usefulness depends on context; for example, a highly capable model that cannot run on-premises or meet EU compliance standards may be unsuitable for certain clients.
Importantly, the benchmark re-ranks models based on three user profiles: cloud-based, sovereign edge (on-premises), and compliance-focused. This approach reveals that models ranked highest for one profile may fall significantly in others, underscoring that there is no one-size-fits-all solution. The developers stress that this is an early-stage framework, with ongoing methodological refinement, and does not claim to be a definitive authority yet.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Why Model Selection Depends on User Needs
This development matters because it shifts the focus from chasing the top-ranked capability models to considering deployment environment, compliance, and reliability. For defense and intelligence agencies, deploying an AI system that is powerful but incompatible with their operational constraints can be ineffective or even dangerous. The VigilSAR Benchmark’s approach encourages tailored model selection, reducing the risk of misapplication and promoting safer, more responsible use of AI in sensitive areas.

Personal AI Servers: A Guide to Building Private AI Infrastructure for Secure, Offline and Self-Hosted Local LLMs for Data Privacy
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations of Capability-Only Leaderboards
Traditional AI benchmarks often prioritize raw capability, ranking models solely on performance on a set of tasks. However, such rankings do not account for deployment realities like hardware constraints, regulatory compliance, or robustness against adversarial inputs. VigilSAR’s approach explicitly incorporates these factors, reflecting the actual conditions under which models are used in defense settings. The benchmark’s development responds to growing awareness that capability alone is insufficient for practical deployment, especially in regulated or secure environments.
“There is no one-size-fits-all model. The right choice depends on your specific operational needs, environment, and compliance requirements.”
— Thorsten Meyer, founder of VigilSAR
defense AI model reliability tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties About Benchmark Methodology and Adoption
It is not yet clear how widely the VigilSAR Benchmark will be adopted by defense agencies or AI providers. The methodology is still evolving, and the impact of the benchmark on procurement decisions remains to be seen. Additionally, the extent to which this approach influences industry standards or regulatory frameworks is still uncertain, as it is an early-stage initiative.

AI Forensics
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for VigilSAR and Defense AI Evaluation
VigilSAR plans to refine its methodology based on community feedback and expand the scope to include more knowledge domains and deployment scenarios. Further, it aims to promote awareness among defense and regulated sectors about the importance of multi-criteria evaluation. Watch for updates on how the benchmark influences procurement practices and whether more models will be tailored for specific operational contexts.

RCTCBRZVTW Intelligent AI Edge Computing Box 6 Channel Video Algorithm Analytics Intelligence(8-Way 24 generalized algorithms)
Stability: Long-term stable use
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why does VigilSAR emphasize multiple axes instead of capability alone?
Because real-world deployment depends on factors like reliability, safety, compliance, and hardware constraints, not just raw performance. The multi-criteria approach helps identify models suitable for specific operational needs.
Can a model ranked low on capability still be useful?
Yes, if it meets other critical criteria such as compliance, robustness, and deployability, especially in sensitive or regulated environments.
Is the VigilSAR benchmark applicable outside defense?
While designed for defense and intelligence, the principles of multi-criteria evaluation could be relevant for other regulated sectors requiring tailored AI solutions.
Will this benchmark replace traditional capability leaderboards?
No, it complements existing benchmarks by adding a focus on deployment realities, but capability rankings remain relevant for certain applications.
How will this affect AI model development?
Developers may prioritize robustness, safety, and deployment features alongside capability, leading to more balanced and practical AI models for sensitive use cases.
Source: ThorstenMeyerAI.com